
안 쓰던 블로그
분류와 결정트리, 결정트리 시각화 본문
분류(Classification)
학습 데이터의 피처와 레이블값(결정 값, 클래스 값)을 학습, 모델을 생성하고, 이렇게 생성된 모델에 새로운 데이터 값이 주어졌을 때 미지의 레이블 값을 예측하는 것
나이브 베이즈(베이즈 통계 기반)
로지스틱 회귀(독립변수, 종속변수의 선형 관계성 기반)
결정 트리(데이터 균일도에 따른 규칙 기반)
신경망(심층 연결 기반)
앙상블(서로 다르거나 같은 머신러닝 알고리즘 결합, 결정 트리를 기반)
등등..
결정 트리와 앙상블
결정 트리는 데이터 스케일링이나 정규화 등의 사전 가공 영향이 적고, 쉽고 유연하게 적용되지만 예측 성능 향상을 위해서는 복잡한 규칙 구조를 가져야 한다. 이로 인한 overfitting과적합 때문에 오히려 예측 성능이 저하되는 단점이 있다
앙상블은 매우 많은 여러 개의 예측 성능이 상대적으로 떨어지는 학습 알고리즘들(약한 학습기)을 결합하여 예측 성능을 향상한다. 결정 트리의 단점은 약한 학습기가 되기 때문에 앙상블에서는 오히려 장점이 된다
결정트리(Decision Tree)
데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 기반의 분류 규칙을 만드는 트리 기반 분류 알고리즘
if else를 자동으로 찾아내 예측을 위한 규칙을 만든다->스무고개같은 느낌
-새로운 규칙 조건(부모 노드)마다 규칙 노드 기반의 서브 트리(자식 노드)를 생성한다
-리프 노드는 결정된 분류값이다
어떤 기준으로 규칙을 만들어야 효율적인 분류가 되는지 잘 고민하는 게 핵심
균일도 기반 규칙 조건
균일도가 높은 그룹을 기준으로 규칙을 만든다
예) 노란색 원은 6개, 빨간색/파란색은 원, 세모, 네모가 섞여 있으면 첫 번째로 만들어지는 규칙 조건: if색깔=='노란색'
균일도 측정 방법
정보 이득(Information Gain)
-엔트로피(=데이터 집합의 혼잡도) 기반. 서로 다른 값이 섞여 있으면 엔트로피가 높고, 같은 값이 섞여 있으면 엔트로피가 낮다
-정보 이득 지수는 1에서 엔트로피 지수를 뺀 값(1-엔트로피 지수)
-정보 이득이 높은 속성을 기준으로 분할한다
지니 계수
-본래 경제학에서 불평등 지수를 나타낼 때 사용. 0이 가장 평등, 1로 갈수록 불평등
-머신러닝에서는 데이터가 다양한 값을 가질수록 평등, 특정 값으로 쏠리면 불평등
-다양성이 낮을수록 균일도가 높다=1로 갈수록 균일도가 높다
결정 트리의 규칙 노드 생성 프로세스
1. 데이터 집합의 모든 아이템이 같은 분류에 속하는지 확인
2-1. if true: 리프 노드로 만들어서 분류 결정
2-2. else: 데이터를 분할하는 데 가장 좋은 속성과 분할 기준 찾기(정보 이득or지니계수 이용)
3. 해당 속성과 분할 기준으로 데이터 분할하여 규칙 브랜치 노드 생성
4. 모든 데이터 집합의 분류가 결정될 때까지 반복 수행
결정 트리의 특징
장점: 쉽고 직관적이다
단점: 과적합overfitting 으로 알고리즘 성능이 떨어진다(데이터가 커지면 반복 수행이 늘어나서 효율 낮아짐)->트리 크기를 사전에 제한하는 튜닝이 필요함
결정 트리 주요 하이퍼 파라미터
max_depth: 트리의 최대 깊이 규정. 디폴트는 None, 데이터 개수가 min_samples_split보다 작아질 때까지 반복하여 깊이 증가. 깊이가 너무 깊어지면 최대 분할 개수=과적합할 수 있으므로 적절한 제어 필요
max_features: 최적의 분할을 위해 고려할 최대 피처 개수. 디폴트는 None=데이터 세트의 모든 피처 사용하여 분할 수행. int, float, sqrt, auto, log, none에 따라 피처 선정할 기준이 달라진다(개수, 퍼센트, 전체피처의 루트, 전체피처의 로그 등)
min_samples_split: 노드를 분할하기 위한 최소한의 샘플 데이터 수, 과적합 제어하는 데 사용. 디폴트는 2, 작을수록 분할되는 노드 많음(=과적합 가능성 증가)
min_sample_leaf: 말단 노드가 되기 위한 최소한의 샘플 데이터 수
max_leaf_nodes: 리프 노트의 최대 개수
결정트리 모델의 시각화 - Graphviz
공식 홈페이지: graphviz.org/
stable버전 다운로드 받고 설치
시스템->고급 시스템 설정->환경변수->사용자 변수 path 새로만들기 후 설치경로\bin폴더 등록(디폴트 C:\Program Files\Graphviz\bin)->시스템 변수 path 편집, 새로 만들기 후 bin폴더 아래 dot.exe 등록(C:\Program Files\Graphviz\bin\dot.exe)
cmd관리자모드->dot -version해서 대기 뜨면 정상, 아니면 dot -c 후 dot -version 다시
그리고 주피터 노트북 실행
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
# DecisionTree Classifier 생성
dt_clf = DecisionTreeClassifier(random_state=156)
# 붓꽃 데이터를 로딩하고, 학습과 테스트 데이터 셋으로 분리
iris_data = load_iris()
X_train , X_test , y_train , y_test = train_test_split(iris_data.data, iris_data.target,
test_size=0.2, random_state=11)
# DecisionTreeClassifer 학습.
dt_clf.fit(X_train , y_train)사이킷런의 DecisionTreeClassifier 사용
붓꽃 데이터를 로딩, 분리, 학습(foxtrotin.tistory.com/396)
학습된 classifer 만들기
from sklearn.tree import export_graphviz
# export_graphviz()의 호출 결과로 out_file로 지정된 tree.dot 파일을 생성
export_graphviz(dt_clf, out_file="tree.dot", class_names=iris_data.target_names , \
feature_names = iris_data.feature_names, impurity=True, filled=True)export_graphviz는 학습된 classifer입력을 하면 읽어서 dot파일을 생성
class_names와 feature_names를 꼭 넣어주어야 한다
<max_depth 제약 없는 Decision Tree 시각화>
import graphviz
# 위에서 생성된 tree.dot 파일을 Graphviz 읽어서 Jupyter Notebook상에서 시각화
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)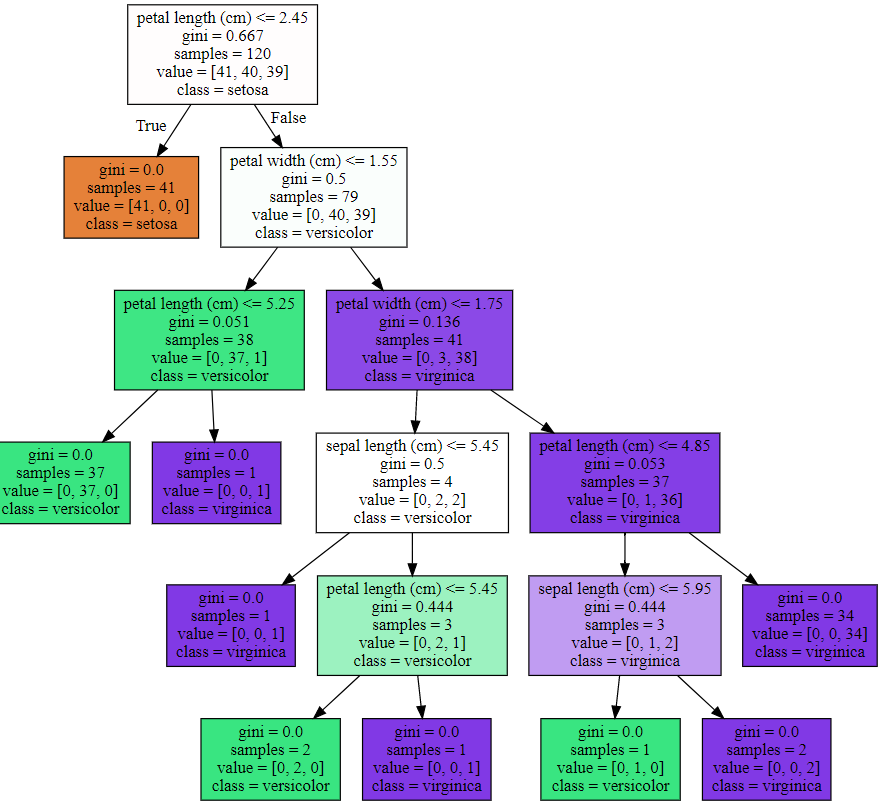
각각의 규칙을 가진 추리 모델들이 만들어진다
조건: petal length(cm)<=2.45 와 같이 조건이 있는 것은 자식 노드를 만들기 위한 규칙 조건. 이 조건이 없으면 리프 노드 =
gini: 다음의 value=[] 로 주어진 데이터 분포에서의 지니계수
samples: 현 규칙에 해당하는 데이터 건수
value=[]: 클래스 값 기반의 데이터 건수(이번 예제인 붓꽃의 경우 0: Setosa, 1 : Veericolor, 2: Virginia 를 나타냄. value=[1,2,3]이면 각각 1, 2, 3개)
class: value 리스트 내에 가장 많은 건수를 가진 결정값
색깔: 진할 수록 균일화가 잘 되어 있다
<max_depth=3으로 제한한 Decision Tree 시각화>
# DecicionTreeClassifier 생성 (max_depth = 3 으로 제한)
dt_clf = DecisionTreeClassifier(max_depth=3 ,random_state=156)
dt_clf.fit(X_train, y_train)
# export_graphviz( )의 호출 결과로 out_file로 지정된 tree.dot 파일을 생성함
export_graphviz(dt_clf, out_file="tree.dot", class_names = iris_data.target_names,
feature_names = iris_data.feature_names, impurity=True, filled=True)
import graphviz
# 위에서 생성된 tree.dot 파일을 Graphiviz 가 읽어서 시각화
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
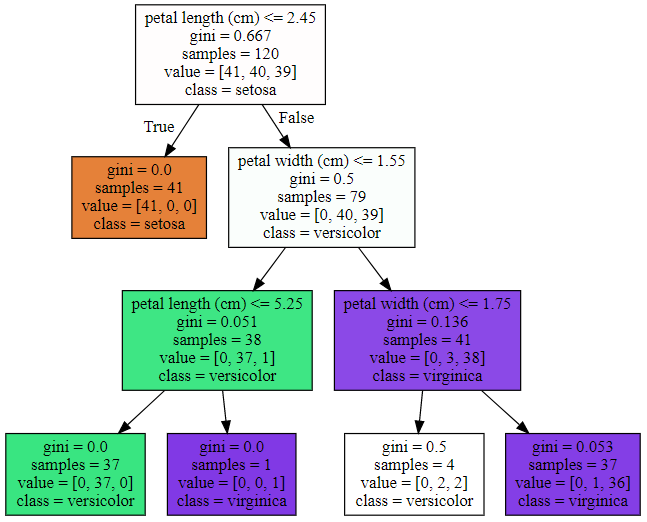
깊이가 3으로 제한된 트리가 생성
<min_samples_split=4인 트리>
# DecicionTreeClassifier 생성 (min_samples_split=4로 상향)
dt_clf = DecisionTreeClassifier(min_samples_split=4 ,random_state=156)
dt_clf.fit(X_train, y_train)
# export_graphviz( )의 호출 결과로 out_file로 지정된 tree.dot 파일을 생성함
export_graphviz(dt_clf, out_file="tree.dot", class_names = iris_data.target_names,
feature_names = iris_data.feature_names, impurity=True, filled=True)
import graphviz
# 위에서 생성된 tree.dot 파일을 Graphiviz 가 읽어서 시각화
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)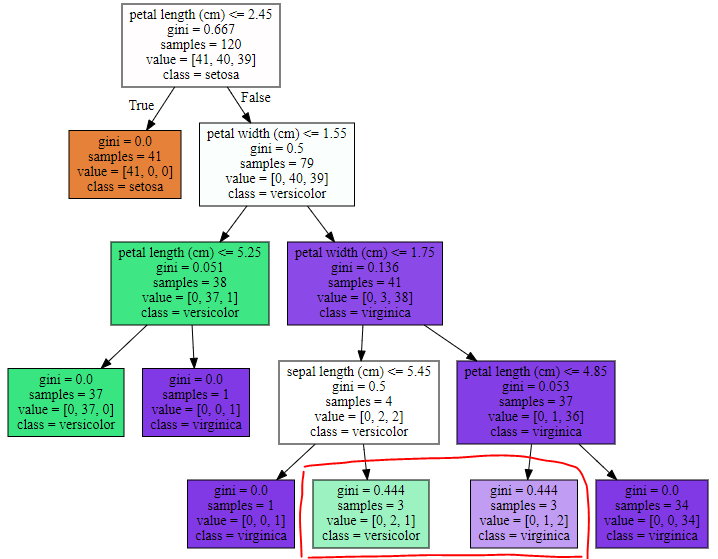
samples가 3이고 min_samples_split=4니까 서로 다른 class값이 더 있어도 또 다시 split하지 않고 class를 결정했다
결정 트리의 Feature 선택 중요도
-사이킷런의 DecisionTreeClassifier 객체는 featureimportances 속성으로 학습/예측을 위해서 중요한 Feature들을 선택할 수 있는 정보 제공
-기본적으로 ndarray형태로 값을 반환하며 피처 순서대로 값이 할당된다
import seaborn as sns
import numpy as np
%matplotlib inline
# feature importance 추출
print("Feature importances:\n{0}".format(np.round(dt_clf.feature_importances_, 3)))
# feature별 importance 매핑
for name, value in zip(iris_data.feature_names , dt_clf.feature_importances_):
print('{0} : {1:.3f}'.format(name, value))
# feature importance를 column 별로 시각화 하기
sns.barplot(x=dt_clf.feature_importances_ , y=iris_data.feature_names)
'머신러닝 > 머신러닝' 카테고리의 다른 글
| 앙상블 개요, 보팅 (0) | 2021.02.07 |
|---|---|
| 결정 트리 과적합, 결정 트리 실습 (0) | 2021.01.31 |
| [평가] kaggle - Pima 인디언 당뇨병 예측 (0) | 2021.01.25 |
| 평가(Evaluation)_2 (0) | 2021.01.24 |
| 평가(Evaluation)_1 (0) | 2021.01.24 |



