
안 쓰던 블로그
다중 슬롯머신 문제 (Multi-Amred Bandits, MAB) with UCB1(Upper Confidence Bound1) 본문
다중 슬롯머신 문제 (Multi-Amred Bandits, MAB) with UCB1(Upper Confidence Bound1)
proqk 2021. 6. 24. 18:50
이전 글: 다중 슬롯머신 문제 with Epsilon-Greedy
https://foxtrotin.tistory.com/501
다중 슬롯머신 문제 (Multi-Amred Bandits, MAB) with Epsilon-Greedy
다중 슬롯머신 문제 (Multi-Amred Bandits, MAB) 여러 개의 팔을 가진 슬롯머신이 있다. 슬롯머신의 팔마다 코인이 나오는 확률은 정해져 있지만, 확률값은 미리 알 수 없다. 제한된 횟수 안에서 가장 많
foxtrotin.tistory.com
다중 슬롯머신 문제란, 어떤 슬롯머신의 팔을 당겨야 가장 많은 돈을 벌 것인지에 대해 찾는 문제이다.
문제 해결을 위해서는 탐색과 이용의 균형을 적절하게 맞추는 것이 중요하다. 이전 글에서는 입실론 그리디 방법을 사용해 보았다. 이 글에서는 또 다른 방법인 UCB1을 사용해서 문제를 해결해 본다.
'알파제로를 분석하며 배우는 인공지능' 책을 참고한 글임을 밝힌다.
UCB1
UCB1은 '성공률+바이어스(편향)'를 최대로 만드는 행동을 선택하는 방법이다. 성공률은 '해당 행동의 성공 횟수/해당 행동의 시행 횟수'이다. 편향은 '우연에 의한 성공률의 분포 크기'로 해당 행동의 시행 횟수가 작을수록 커진다.
'성공률+바이어스'은 다음 식으로 구한다.
$$UCB1 = \frac{w}{n} + \sqrt{\left ( \frac{2\times log(t))}{n} \right )^{\frac{1}{2}}}$$
$n$: 해당 행동의 시행 횟수
$w$: 해당 행동의 성공 횟수
$t$: 모든 행동의 시행 횟수의 합
파라미터를 다음 순서에 따라 갱신한다
(1) 선택한 팔의 시행 횟수+1
(2) 성공 시, 선택한 팔의 성공 횟수+1
(3) 시행 횟수가 0인 팔이 존재하는 경우 가치를 갱신하지 않음(0 나누기 불가)
(4) 각 팔의 가치 계산 (위의 식 사용) - 이 때 선택한 팔은 물론 모든 팔의 가치를 갱신한다.
#UCB1
class UCB1():
def initialize(self, n_arms):
self.n = np.zeros(n_arms) #number of attempts of each arm
self.w = np.zeros(n_arms) #number of successes of each arm
self.v = np.zeros(n_arms) #value of each arm
#select arm
def select_arm(self):
#select arms that all n>=1
for i in range(len(self.n)):
if self.n[i] == 0:
return i
return np.argmax(self.v) #select high value arm
#update parameter
def update(self, chosen_arm, reward, t):
self.n[chosen_arm] += 1 #attempts of the selected arm + 1
if reward == 1.0:
self.w[chosen_arm] += 1 #if success, successes of the selected arm + 1
#if there is an arm with the number of attempts 0, value is not updated
for i in range(len(self.n)):
if self.n[i] == 0:
return
#update the value of each arms
for i in range(len(self.v)):
self.v[i] = self.w[i] / self.n[i] + (2*math.log(t) / self.n[i]) ** 0.5
#string info
def label(self):
return 'ucb1'
시뮬레이션 실행
슬롯 머신을 생성하고, 그래프를 그리는 부분 및 전체적인 코드는 이전 글의 코드와 같다. 다만 두 알고리즘의 비교를 위해서 각 알고리즘을 실행한 뒤에 그래프에 동시에 그려주도록 변경하였다.
#select arm
arms = (SlotArm(0.3), SlotArm(0.5), SlotArm(0.9))
#set algorithm
algos = (EpsilonGreedy(0.1), UCB1())
#run
for algo in algos:
result = play(algo, arms, 1000, 250)
#draw graph
df = pd.DataFrame({'times': result[0], 'rewards': result[1]})
mean = df['rewards'].groupby(df['times']).mean()
plt.plot(mean, label = algo.label())
plt.xlabel('Step')
plt.ylabel('Average Reward')
plt.legend(loc = 'best')
plt.show()
그래프 결과는 다음과 같다.
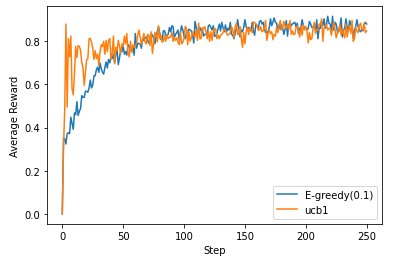
평균 보상은 단계가 커질수록 비슷해지지만, UCB1쪽이 게임 시작 지점에서의 보상이 높은 것을 알 수 있다.
전체 코드
https://github.com/proqk/MAB-with-Epsilon-Greedy-and-UCB1
proqk/MAB-with-Epsilon-Greedy-and-UCB1
Multi-Amred Bandits(MAB) with Epsilon-Greedy and UCB1 - proqk/MAB-with-Epsilon-Greedy-and-UCB1
github.com
'머신러닝 > 머신러닝' 카테고리의 다른 글
| 사전 훈련된 CNN 사용하기 (Using a pretrained CNN) (0) | 2021.07.16 |
|---|---|
| model.summary() 의 ValueError: This model has not yet been built 에러 (0) | 2021.07.16 |
| 다중 슬롯머신 문제 (Multi-Amred Bandits, MAB) with Epsilon-Greedy (0) | 2021.06.24 |
| 소규모 데이터셋에서 CNN 훈련하기(Kaggle - Dogs vs. Cats) (1) | 2021.05.12 |
| CNN(convolutional neural network - 합성곱 신경망) (2) | 2021.04.08 |



