
안 쓰던 블로그
Faster RCNN 본문
Fast RCNN
-SPP Layer를 ROI Pooling Layer로
SPP-Net과 비슷하지만 L0,L1,L2로 나누지 않고 7x7크기 하나의 레이어를 가지고 벡터가 만들어짐
-End-to-End Network Learning을 시켰다(ROI Proposal은 제외)
Multi-task loss함수로 Classification과 Regression을 함께 최적화
문제점: End-to-End Learning에 ROI Proposal이 되지 않았고, 그것 때문에 네트워크에 포함시켰을 때는 시간이 오래걸렸다. 네트워크를 포함하려는 요구에 따라 해결책이 나왔고, 그것이 Faster RCNN이다
Faster RCNN
Fater RCNN = RPN(Region Proposal Network)+Fast RCNN
-Selective Search를 Neural Network 구조로 변경
-GPU 사용으로 빠른 학습/Inference
-End to End Network 학습
기본 Selective Search가 수행하던, 오브젝트가 있을 법한 위치를 추천하고 ROL Pooling으로 매핑하는 과정은 같다. 그런데 Selective Search는 CPU를 사용하다 보니까 시간이 느린 문제가 생겼다. 그래서 Selective Search가 하는 일을 딥러닝의 네트워크 구조로 바꾸어 GPU를 사용하게 만들었다. 결과적으로 다른 외부 모듈 없이 오직 네트워크로만 이루어지게 되었다
문제점: Selective Search를 대체하기 위한 RPN구현 문제->데이터로 주어질 피처는 pixel값, Target은 Ground Truth Bounding Box밖에 없는데 어떻게 Selective Search수준의 Region Proposal을 할 수 있지?
->(Reference) Anchor Box사용. Object가 있는지 없는지의 후보 Box를 잡는다. Anchor Box를 먼저 잡아놓고, 그 영역에 오브젝트가 있는지 없는지를 네트워크 바운딩 박스를 통해서 이미지가 들어오는대로 학습하며 계속 확인하는 방식
Anchor Box
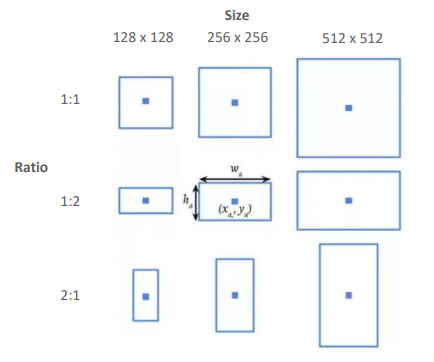
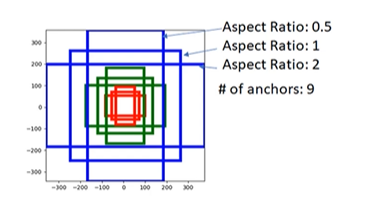
총 9개, 3개의 서로 다른 크기(128x128, 256x256. 512x512), 3개의 서로 다른 ratio(1:1, 1:2, 2:1)로 구성된다
장점은 오브젝트가 겹쳐 있을 때에도 서로 다르게 생긴 Anchor box가 각각의 오브젝트들을 포함할 수 있기 때문에 탐지할 수 있다
이미지와 Feature Map에서 Anchor Box 매핑
위의 십자 모양의 Anchor box들(Anchors)이 이미지 위에 촘촘하게 올라간다
그리고 Anchor box위에 오브젝트가 있냐없냐를 따져본다
이미지가 Anchor box의 사이즈도 맞춰서 작아진다
만약 이미지가 600x800이면 16만큼 작아지고, (800/16)*(600/16)=1900만큼 이미지의 그리드 포인트가 생기는 것
그리드 포인트마다 Anchor box가 올라간다. 당연히 중간 부분으로 갈 수록 겹쳐지면서 더 짙어진다
이렇게 하면 총 Anchor box는 1900*9=17100개가 생긴다(9는 Anchor box에 겹쳐진 총 box의 개수가 9개라서)
'머신러닝 > 머신러닝' 카테고리의 다른 글
| Linear Regression 선형 회귀 (0) | 2021.01.21 |
|---|---|
| RPN (0) | 2021.01.20 |
| RCNN, SPM, SPP, SPPNet (0) | 2021.01.17 |
| OpenCV를 활용한 영상 처리 (0) | 2021.01.17 |
| OpenCV를 활용한 이미지 처리 (0) | 2021.01.17 |

