
안 쓰던 블로그
파이썬 beautifulsoup로 웹툰 크롤링, 다운로드 하기 본문
*본 글은 공부목적으로만 참고하세요
파이썬 크롤링 시리즈
네이버 웹툰 이미지 크롤링, 저장하기: 현재글
셀레니움으로 웹 게임 자동 매크로 만들기: foxtrotin.tistory.com/179
네이버 실시간 검색어 가져오기: foxtrotin.tistory.com/267
네이버 웹툰 요일별 크롤링: foxtrotin.tistory.com/328
사용할 모듈
1. urllib: 내장 모듈. 파이썬에서 웹과 관련된 데이터를 쉽게 이용할 수 있게 한다. 4개 중에 request사용
2. beautifulsoup: 파싱을 도와준다
3. os: 내장 모듈. 운영체제에서 제공되는 기능을 파이썬에서 수행할 수 있게 함
모듈 설치
파이썬이 있는 디렉토리-Scripts폴더에서 cmd키고 pip install beautifulsoup4
크롤링
1. 크롤링 할 웹툰 주소로 웹 페이지 요청
html = urllib.request.urlopen("https://comic.naver.com/webtoon/list.nhn?titleId=725586&weekday=fri")
soup = BeautifulSoup(html.read(),"html.parser") #웹 페이지 파싱
html.close() #닫기
2. 웹툰 제목 따기
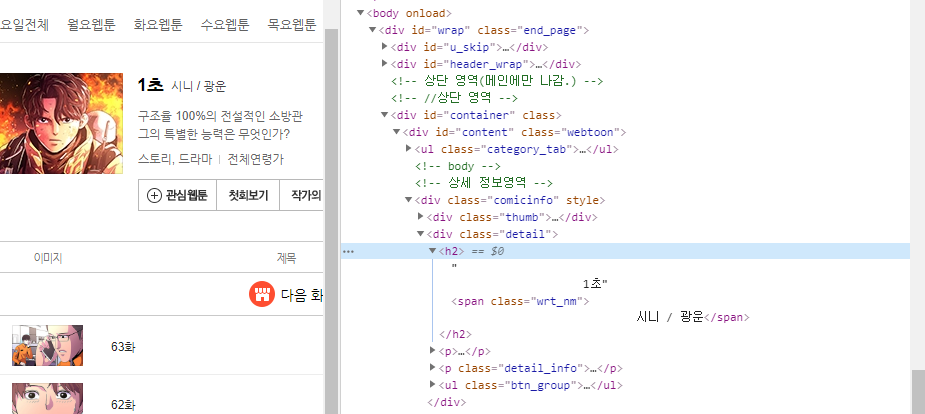
웹툰 제목은 "comicinfo"라는 class에 담겨져있다
comic_title = soup.select('.comicinfo h2')[0].text.split()[0]comicinfo의 h2태그를 따면 ['1초', '시니', '/', '광운'] 이 나온다
그 중에 [0]번째에 있는 제목만 저장해준다
comic_title = soup.find("div", {"class", "detail"}).find("h2").text.split()[0]이런 방법도 가능하다
div태그의 detail이라는 클래스 안에, h2를 찾아서 각 단어를 나누고 [0]번째를 가져오는 방법
3. 다운로드 받을 폴더 만들기
os.chdir("/Users/proqk/Downloads/") #다운로드 폴더
dir = comic_title
if not os.path.isdir(dir):
os.mkdir(dir)
print(comic_title+" 디렉토리 생성")
else:
print("같은 이름의 디렉토리가 이미 있음")
os.chdir("/Users/proqk/Downloads/"+dir) #다운로드 받을 폴더로 이동다운로드 받을 폴더 주소를 지정하고 그 폴더에 웹툰 제목의 폴더를 만든다
만든 폴더로 이동한다
4. 최신 10개화 링크를 리스트에 저장
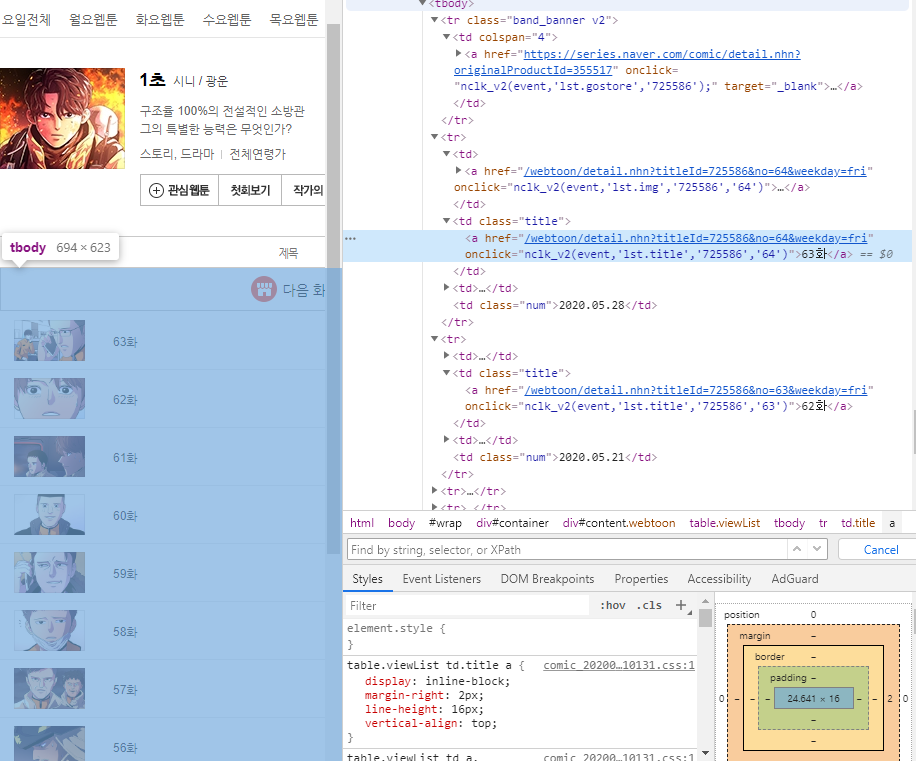
각 화 링크는 <td>태그 안의 <a>태그에 있다
근데 <a>태그를 다 불러오면 맨 위에 '다음화를 미리 만나보세요' 링크도 같이 딸려오기 때문에
그 부분은 패스해준다
comic_list=[]
tmp_list=soup.select('td>a') #<td>안에 <a>태그에
for i in tmp_list:
if('https' in i['href']): #다음 화를 미리 만나보세요 링크 패스
continue
comic_list.append(i['href'])
comic_list = sorted(set(comic_list))
for i in range(len(comic_list)):
print(comic_list[i])여기까지 하면 리스트 안에 각 화에 대한 링크가 들어가게 되는데
그냥 가져오면 링크가 두 개씩 들어가기 때문에 중복 제거+회차 순서대로 정렬까지 해준다
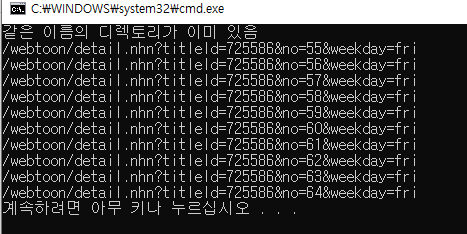
5. 각 회차 제목으로 된 폴더 만들기
for i in range(len(comic_list)):
ep_url = url="https://comic.naver.com"+comic_list[i]
html = urllib.request.urlopen(ep_url)
soup2 = BeautifulSoup(html.read(),"html.parser")
ep = soup2.find('h3') #<h3>이름</h3>
ep_title = re.sub('<.*?>', '', str(ep)) #이름만 남게
if not os.path.isdir(ep_title):
os.mkdir(ep_title)
print(ep_title+" 디렉토리 생성")
else:
print("같은 이름의 디렉토리가 이미 있음")
os.chdir(ep_title) #이동아까 각 회차 링크를 담은 리스트를 돌면서 제목으로 된 폴더에 이미지를 다운받을 것
일단 제목을 따오는데 제목은 h3태그에 있다
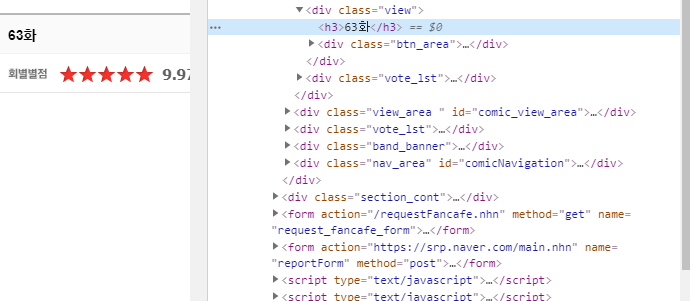
h3태그를 다 가져오면
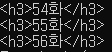
이렇게 가져와지는데, regex 를 이용해서 < 또는 >, /> 를 '' 으로 치환한다
ep_title = re.sub('<.*?>', '', str(ep)) #이름만 남게
제목으로 된 폴더를 만들고, 그 폴더로 이동한다
6. 각 회차의 이미지 저장
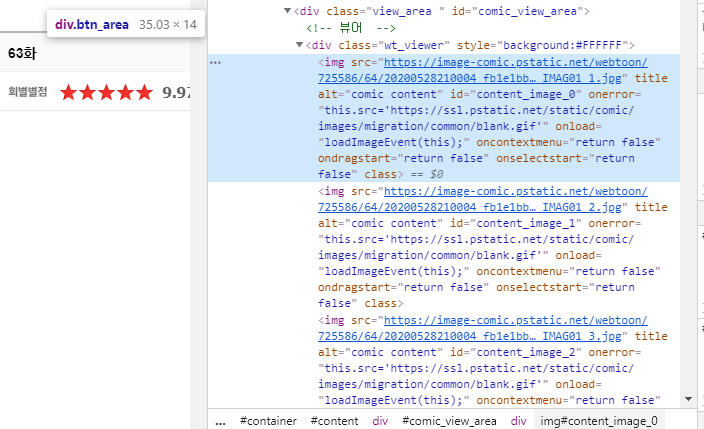
이미지 링크는 div view_area 클래스 안에 src태그에 있다
전부 긁어와서 리스트에 넣어준다
img_div = soup2.find("div", {"class", "wt_viewer"})
img_all = img_div.findAll("img")
num = 1
for j in img_all:
img_path = j.get("src")
img_num = str(num)+".png"
urllib.request.urlretrieve(img_path, img_num)
num = num + 1
print(ep_title+" 다운로드 완료")
os.chdir("..") #상위 폴더로리스트를 돌면서 각 이미지 링크에서 src부분만 분리한다
그리고 각 이미지 제목을 정해준 뒤, 각각의 이름.png로 링크에서 다운로드 해 온다
저장이 끝나면 상위 폴더로 올라가서 다른 회차를 저장할 준비를 한다
7. 전체 코드
from bs4 import BeautifulSoup
import urllib.request
import os, re #태그 제거
#Access Denied 에러 우회
opener=urllib.request.build_opener()
opener.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1941.0 Safari/537.36')]
urllib.request.install_opener(opener)
#크롤링 할 웹툰 주소로 웹 페이지 요청
html = urllib.request.urlopen("https://comic.naver.com/webtoon/list.nhn?titleId=725586&weekday=fri")
soup = BeautifulSoup(html.read(),"html.parser") #웹 페이지 파싱
html.close() #닫기
comic_title = soup.find("div", {"class", "detail"}).find("h2").text.split()[0] #만화 이름
os.chdir("/Users/proqk/Downloads/") #다운로드 폴더
dir = comic_title
if not os.path.isdir(dir):
os.mkdir(dir)
print(comic_title+" 디렉토리 생성")
else:
print("같은 이름의 디렉토리가 이미 있음")
os.chdir("/Users/proqk/Downloads/"+dir) #다운로드 받을 폴더로 이동
comic_list=[]
tmp_list=soup.select('td>a') #<td>안에 <a>태그에
for i in tmp_list:
if('https' in i['href']): #다음 화를 미리 만나보세요 링크 패스
continue
comic_list.append(i['href'])
comic_list = sorted(set(comic_list))
for i in range(len(comic_list)):
ep_url = url="https://comic.naver.com"+comic_list[i]
html = urllib.request.urlopen(ep_url)
soup2 = BeautifulSoup(html.read(),"html.parser")
ep = soup2.find('h3') #<h3>이름</h3>
ep_title = re.sub('<.*?>', '', str(ep)) #이름만 남게
if not os.path.isdir(ep_title):
os.mkdir(ep_title)
print(ep_title+" 디렉토리 생성")
else:
print("같은 이름의 디렉토리가 이미 있음")
os.chdir(ep_title) #이동
img_div = soup2.find("div", {"class", "wt_viewer"})
img_all = img_div.findAll("img")
num = 1
for j in img_all:
img_path = j.get("src")
img_num = str(num)+".png"
urllib.request.urlretrieve(img_path, img_num)
num = num + 1
print(ep_title+" 다운로드 완료")
os.chdir("..") #상위 폴더로
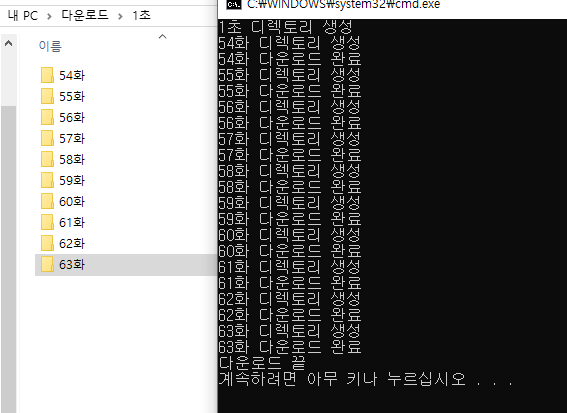
print("다운로드 끝")
이렇게 되면 이미지가 각 폴더에 저장된다
'언어 > 파이썬' 카테고리의 다른 글
| [파이썬] beautifulsoup로 2020년 네이버 실시간 검색어 크롤링 하기 (0) | 2020.09.01 |
|---|---|
| 파이썬-selenium으로 웹 매크로 만들기 (0) | 2020.06.07 |
| VS 파이썬 unresolved import warning 해결 방법 - Visual Studio에서 Python 모듈 설치하기 (0) | 2020.05.30 |
| 파이썬 .2f표현 (0) | 2020.04.07 |
| 파이썬 업다운게임 구현 (0) | 2020.04.07 |


